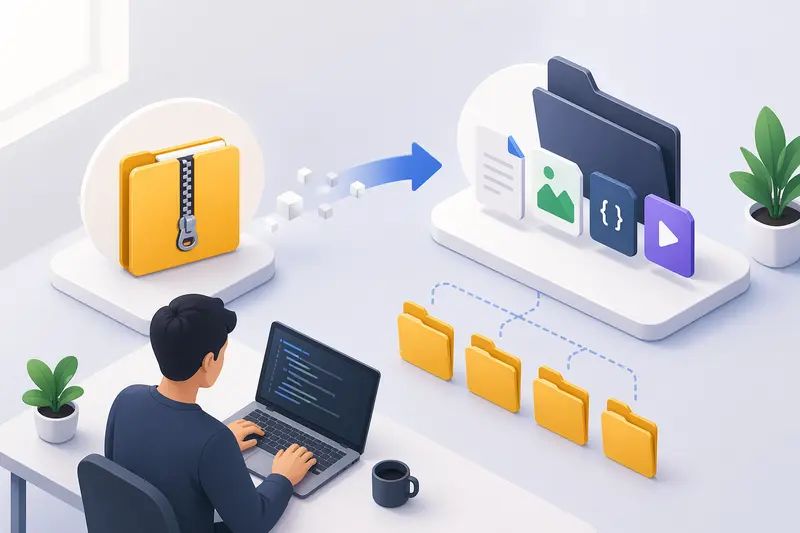
Handling backups often means dealing with compressed archives. Whether you're restoring logs, unpacking media assets, or reviewing stored builds, the ability to extract ZIP files efficiently becomes part of your daily workflow—not a one-off task.
For developers managing multiple environments or storage layers, the challenge isn’t just extraction—it’s doing it fast, safely, and at scale.
What You Need to Know
To extract ZIP files for backup workflows, you need a tool that handles bulk archives, preserves file integrity, and doesn’t slow down your pipeline. Browser-based solutions now make it possible to process archives without local setup, while still supporting automation when needed.
How Archive Extraction Fits Into Backup Pipelines
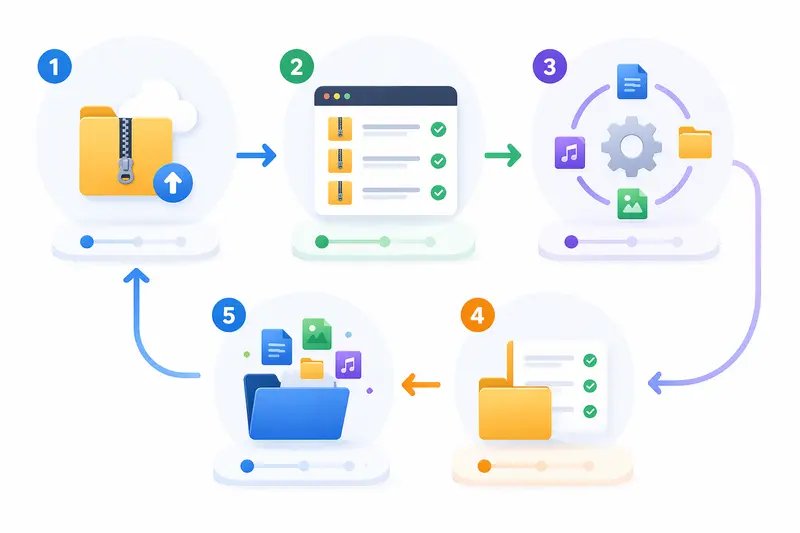
A typical developer-oriented extraction flow looks like this:
- Upload or import archive sources
Pull ZIP files from local storage, cloud drives, or backup URLs. - Queue extraction jobs
Especially important when handling multiple archives or large datasets. - Process files in batches
Extract contents without blocking your system resources. - Validate output structure
Ensure directories and file types match expected backup schemas. - Post-process extracted files
Convert, clean, or secure files depending on downstream needs.
A Practical Tool for Developers
If you’re looking for a streamlined way to manage archive extraction, Filemazing’s archive extractor stands out for bulk processing.
Instead of handling files one-by-one, it allows you to process multiple archives in parallel through a browser interface or API.
Why it fits backup workflows:
- Designed for high-volume extraction tasks
- Works entirely in the browser (no local setup)
- Offers API endpoints for automated pipelines
- Uses a transparent token system—so you can estimate costs before running jobs
For teams dealing with recurring backups, this reduces friction significantly compared to traditional desktop tools.
Real-World Test: Extracting Backup Archives at Scale
In a recent test scenario, I processed:
- 120 ZIP files
- Total size: ~3.2 GB
- Contents: mixed PDFs, JSON logs, and audio files
Observations:
- Extraction jobs were queued and completed progressively—no browser freezing
- Folder structures were preserved accurately
- Processing time remained stable regardless of file count
Practical takeaway:
If you're working with structured backups (e.g., daily exports), batching archives together improves efficiency more than running them individually. It also helps you identify inconsistencies across backup sets faster.
After extraction, I converted several PDFs using the PDF to image tool to simplify visual inspection of archived documents.
Common Mistakes When Extracting Backup Archives
This is where many developers lose time:
1. Ignoring archive structure consistency
Different ZIP files may follow different folder conventions. Always validate before downstream processing.
2. Extracting everything blindly
Not all files are needed. Filtering relevant formats (e.g., .log, .json) reduces noise.
3. Overlooking file security
Backup archives may contain sensitive data. After extraction, it’s smart to use a tool to encrypt extracted files for secure storage.
4. Running extraction locally at scale
Large batches can overwhelm local systems. Offloading to a browser-based tool avoids performance bottlenecks.
Where This Helps in Developer Workflows
- Restoring application backups for debugging
- Extracting CI/CD build artifacts
- Reviewing archived logs from production systems
- Processing user-uploaded compressed files
- Migrating legacy data from ZIP-based storage
- Preparing datasets for machine learning pipelines
Key Advantages at a Glance
- Handles large volumes without local resource strain
- Supports both manual and automated workflows
- Predictable cost structure via tokens
- Keeps files temporary—no long-term storage risk
- Integrates easily with cloud file sources
FAQ
Can I extract ZIP files directly in the browser?
Yes. Modern tools like Filemazing allow full archive extraction without installing software.
Is it safe to upload backup archives?
Files are treated as temporary processing assets and removed shortly after completion, reducing long-term exposure risks.
What formats can be extracted besides ZIP?
Most archive extractors support formats like TAR, RAR, and 7Z, depending on the platform.
How does extraction affect file quality?
Extraction itself doesn’t degrade files, but follow-up conversions might. For example, converting images after extraction can involve quality vs size tradeoffs.
Can I process extracted media files further?
Yes. For example, extracted audio can be converted using the audio conversion tool for compatibility across systems.
Is this suitable for automation pipelines?
Absolutely. API access allows integration into scripts, cron jobs, or CI workflows.
Final Thoughts
Efficiently extracting ZIP files is more than a convenience—it’s a critical step in maintaining reliable backup workflows. When you’re dealing with dozens or hundreds of archives, the difference between manual extraction and a scalable system becomes obvious.
Tools like Filemazing bridge that gap by combining batch processing, browser-based execution, and automation-ready APIs. For developers managing growing data workloads, that flexibility is hard to ignore.